こんにちは。グラフィックファシリテーター®やまざきゆにこです。
【NRIプレゼンツ☆知っておきたいデータサイエンス用語】
野村総研 未来創発センター「データサイエンスラボ」さまの新しい取り組み NRI「データサイエンス用語」の解説動画(絵巻物)第14弾がYouTubeアップされました。今回は「LightGBM(Light Gradient Boosting Machine)」です。
↓動画はこちら
↓用語解説はこちら
https://www.nri.com/jp/knowledge/glossary/lst/alphabet/light_gbm
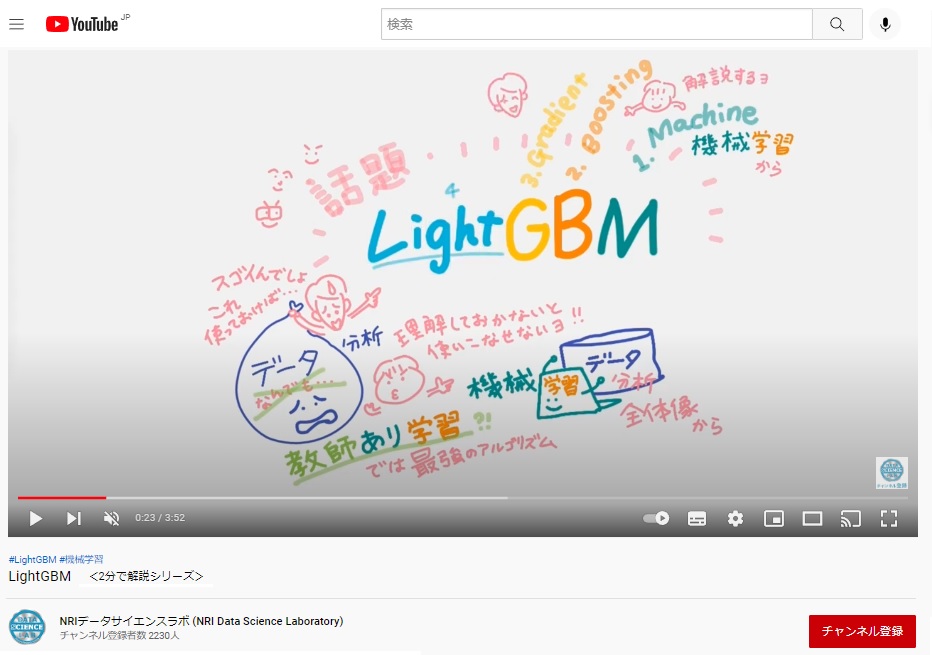
いつもの通りデータサイエンス初心者のわたしが「LightGBMって、ざっくりこんな感じ」を一言で言うと、機械学習でデータ分析といったら「LightGBM」一択!みたいなくらい最強のアルゴリズムの1つらしい。
「LightGBM」が登場するまでは、精度が高分析アルゴリズムは(正しい呼び名じゃないけど「GBM」とくくっちゃいますが、代表的なのはXGBoost)、PCが動かなくなるくらい重かったそう。それをMicrosoftさんが、めちゃくちゃ軽くLightにしてくれたのが「LightGBM」。普通のPCでもデータ分析でいるようになっちゃたのだそう。
ですが、「LightGBMを使っておけば、データ分析は何でもできる」と思い込んで使っちゃってる人もいるらしい…。ということで、今回は基本的な「そもそも機械学習の全体像を理解して」「分析の目的にあわせて」「扱うデータの特徴やそれぞれの分析の種類を理解しましょう」というのが前半です。だから「データ分析初心者」や「機械学習って何?」という人にも参考になると思います。
ただ、制作ウラ話として、今回はあまりの長編すぎて、ヒーヒー制作した動画の後半がYouTubeにアップしきれなかったとのこと(涙)。ということで、このサイトで全編を静止画でアップしておきます。いつものように、やまざきゆにこの「LightGBMって、ざっくりこんな感じ」解説付きです。ちなみに何度もわたしはBGM♪と言い間違いしてました…。

毎度、データサイエンスをかじっている頼りないパパと天才キッズの掛け合い動画。今回もパパが、天才キッズに一括されるところからスタートです。
パパ「LightGBMでデータ分析は何でもできるんでしょ」
天才キッズ「教師あり学習で使うんだよ。機械学習の全体像から理解してないと使いこなせないよ」
LightGBMの後ろから
1、M Machine 機械学習
2、B Boosting ブースティング
3、G Gradient 勾配=誤差
4、Light 軽い!
の順番で説明するね。もう少し具体的に書くと
1、M Machine 機械学習
↓Boostingを説明する前に「分類」と「決定木」を解説
2、B Boosting ブースティング
3、G Gradient 勾配=誤差
↓GBMは精度は高いが重い、そこで
4、Light 軽い!
・軽くなった理由は4つ
・「最強のアルゴリズム」と呼ばれるのは、Lightなだけが理由じゃない
・覚えておきたい3つのハイパーパラメータ
の順番で説明するね。
1、M Machine 機械学習
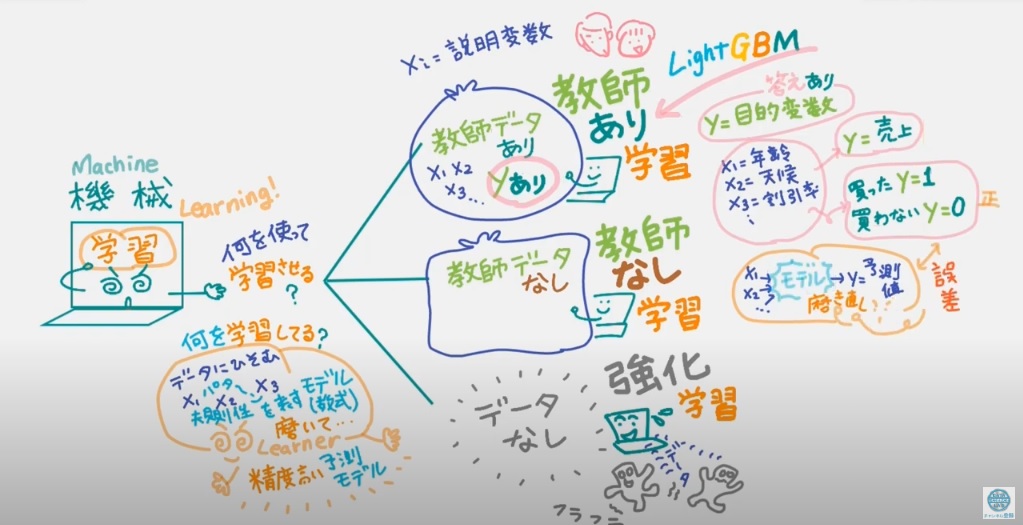
機械学習は「どんなデータを使って学習させるか」で大きく3つある
①教師データがある 教師あり学習
②教師データが無い 教師なし学習
③最初からデータ無し 強化学習:ロボットなどが試行錯誤しながら動作するそのデータをもとに学習させる
①と②については、もう少し詳しく説明すると
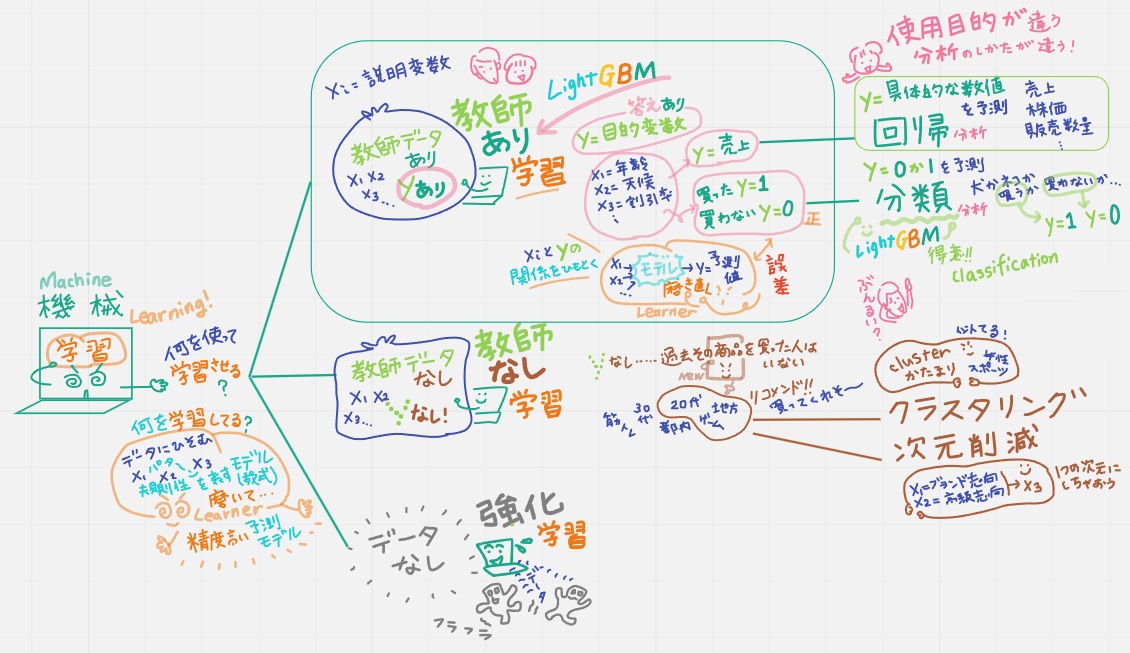
①教師データありとは
説明変数x1,x2,x2,……と目的変数yという答えがそろっているデータが「教師データあり」。yに影響を与えているかもしれない説明変数の例は x1=年齢、x2=天候、x3=割引率、、、、といったもの。
・「教師あり学習」の代表的なデータ分析の手法:回帰と分類
yに2通りある。つまり「分析の目的」がそれぞれ違う。
y=具体的な数値を予測する(売上、株価、販売数量…):回帰分析
y=0か1(犬か猫か/買うか買わないか):分類
・「教師あり学習」で機械学習は何を学習しているかというと
データの中に潜むxiとyの関係を表すモデル(数式)を見つけて、yの予測値を出して、正解yと比較して、その誤差を埋めるように、さらに学習してモデルを、より精度の高い予測モデルへと磨き上げているんだ。
②教師データ無しとは
yが無いデータ。例えば「y=過去にその商品を買った人」がいないといったデータ。
・「教師なし学習」で機械学習は何を学習しているかというと
「y=過去にその商品を買った人」はいないけれど、機械学習は、データ:変数xiの背景にあるパターンや構造を見つけて「こんな人たちなら買ってくれそう」というモデルを導き出す。
・「教師なし学習」の代表的なデータ分析の手法:クラスタリングと次元削減
クラスタリングとは、似ている変数を「クラスター=塊」にすること。
次元削減とは、例えば2つの変数「x1=ブランド志向」「x2=高級志向」は似ているから1つの変数にすること。
以上、「機械学習」と一言で言っても、「手元にあるデータ」や「使用目的」によって「分析の仕方」が違うんだよ。
↓Boosting を説明する前に「分類」と「決定木」を解説
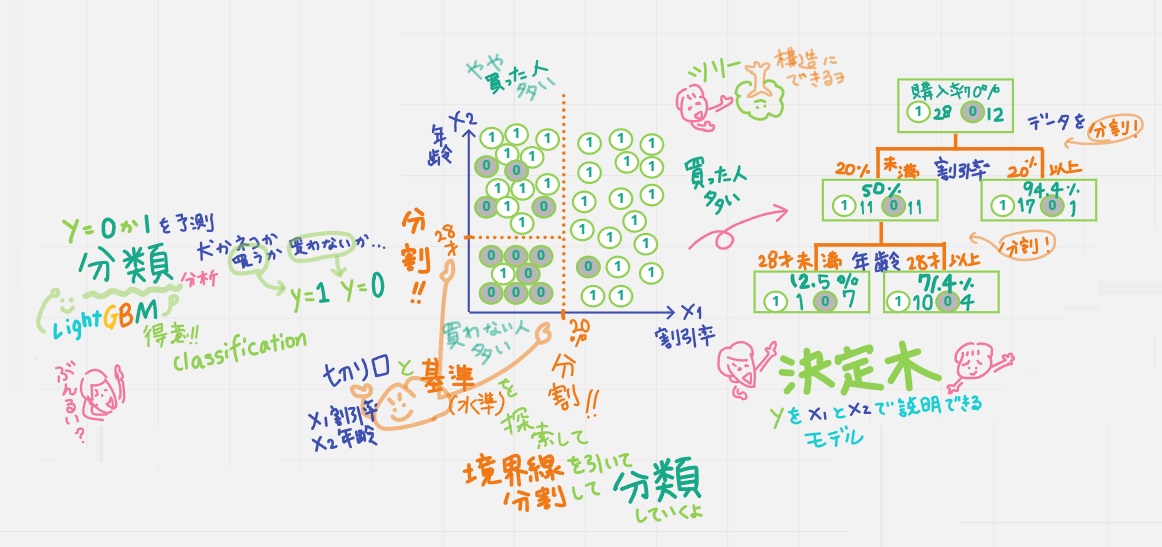
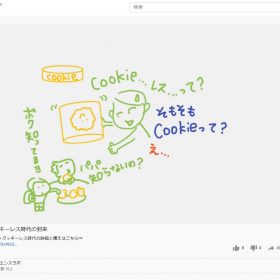
LightGBMは教師データを使って学習する「分類」問題が得意なアルゴリズム。
パパ「分類って、クラスタリングと似てるけど…」
天才キッズ「分類はclassification=クラスごとに分類すること。上の真ん中の図を見てね。例えば「買うy=1/買わないy=0」としたとき、図に0または1と書かれた40人のデータが分布されているとして、
機械学習では、目的変数xiの分岐が最適(最大)になるよう、説明変数の種類(切り口)とその分割の基準(水準)を探索していくんだ。こうして境界線を引いて分割してい「分類」していくよ」
これはツリー構造にも表せるよ。それが右の絵。決定木という。分割していくことでデータの分類のルールが生成できるんだ」
2、B Boosting ブースティング
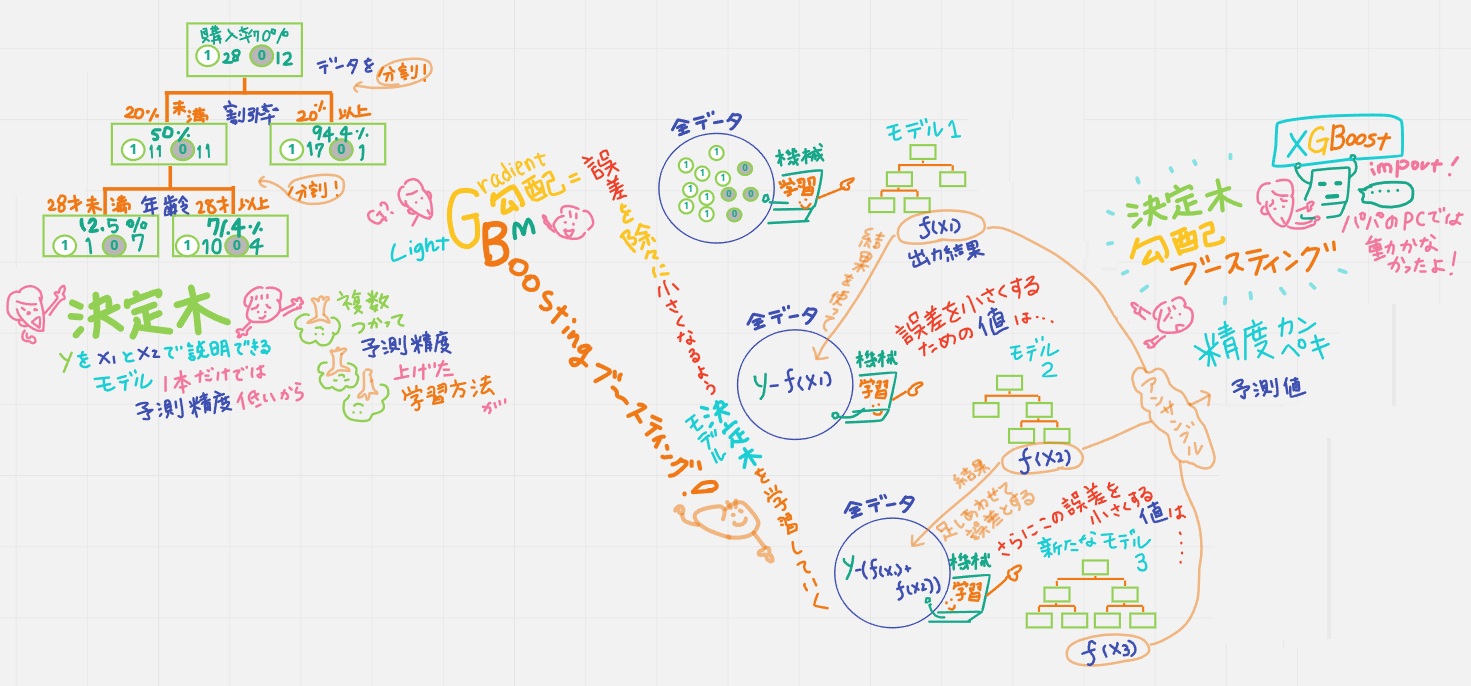
天才キッズ「でも決定木一本では予測精度が低いから、複数使って予測精度を上げていく学習方法を「ブースティング」というんだ。全部のデータを使って学習をするんだけど、1つ前のモデルの結果を使って、予測できなかったデータに重みづけをして学習していくよ。すべての予測値(に係数をかけたもの)を足し合わせて最終的な予測値を出す。アンサンブル学習とも呼ばれていて、かなり精度が高まるんだ」
3、G Gradient 勾配=誤差
天才キッズ「GradientBoostingでは、誤差に注目して、誤差が徐々に小さくなるよう決定木(モデル)を学習してく(磨いていく)。例えば右上の絵。
モデル1=1つ目の決定木の出力結果f(x1)は平均値など適当な値なのだけど、モデル2=2つ目の決定木の学習から、1つ目の決定木の出力結果との誤差 y-f(x1)を小さくするための値を学習していく。
モデル3=3つ目の決定木の学習では、誤差を小さくするための値f(x2)を足し合わせて、誤差 y-(f(x1)+f(x2))を小さくするための値を学習していく。
もう精度はスゴイ!ここまできたら究極もうやることない。
↓GBMは精度は高いが重い、そこで
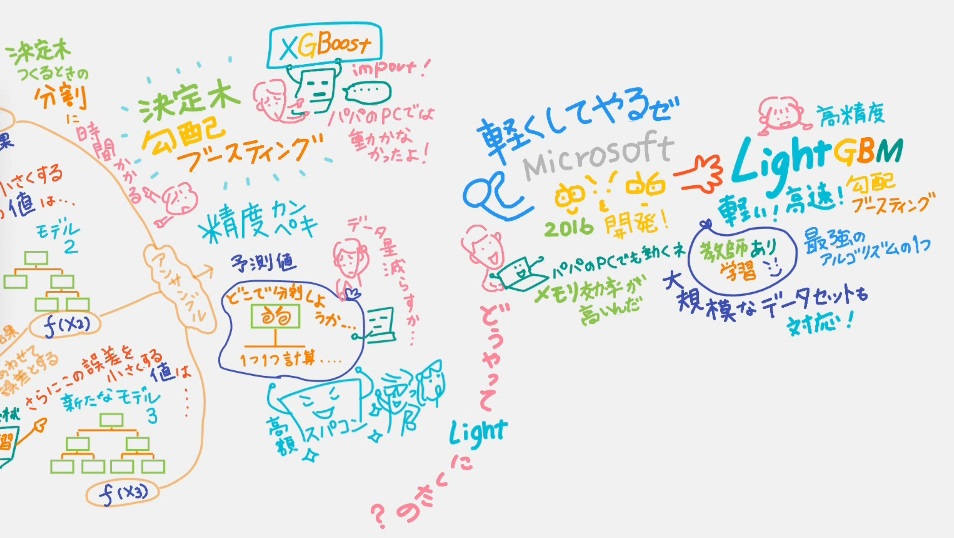
パパ「でも、決定木を使った勾配ブースティングの代表的なアルゴリズムXGBoostは、パパのパソコンじゃ動かなかったよ」
天才キッズ「決定木は分割に時間がかかるから重くなるんだ」
パパ「高額なスパコンがあれば実装できるけど、普通のパソコンで実装するには、分析するデータ量を減らすしかないか…」
天才キッズ「そんな重さを軽くLightにしたのがLightGBM。マイクロソフトが2016年に開発したんだ。高速、高精度。「教師あり学習」の分野では最強のアルゴリズムの1つと言われているよ。メモリ効率も高いからパパのパソコンでも動くよ。大規模なデータも扱えるよ」
4、Light 軽い!
パパ「どうやって Light にしたの?」
天才キッズ「Lightになった理由は大きく4つあるよ」
・Lightになった理由は4つ
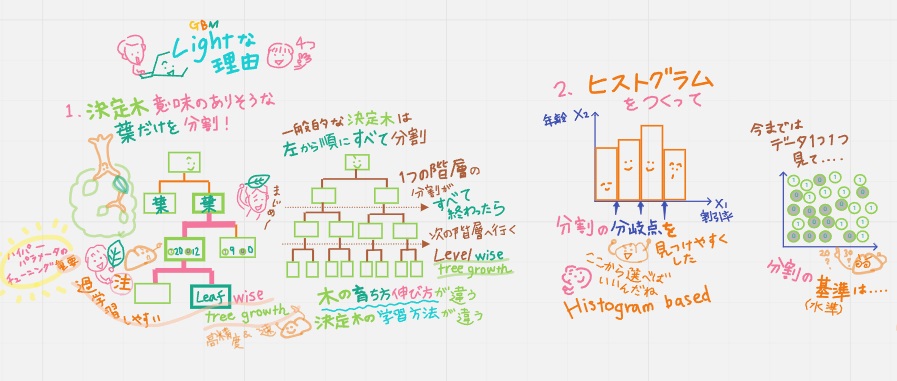
①leaf-wise tree growth
決定木の意味のありそうな葉だけを分割(だからLight)
一般的な決定木は、左から順にすべて分割していく。1つの階層の分割がすべて終わってから次の階層へ行く。leaf-wise tree growth。leaf-wise tree growthのほうが計算も速くて高精度だけど過学習を起こしやすいんだ。
一方、LightGBMは決定木の意味のありそうな葉だけを分割:leaf-wise tree growth。木の育ち方伸び方=決定木の学習方法が違うんだ。ハイパラメータのチューニングが重要になってくるんだけど、その説明はさいごにするね。
②HistogramBased
ヒストグラムをつくって分割の分岐点を見つけやすくした(だからLight)
今まではデータ1つ1つを見て分割の基準(水準)を探索してたけど、ざっくりヒストグラムにすると分岐点から分割の基準(水準)を選べばよくなり速くなったよ。
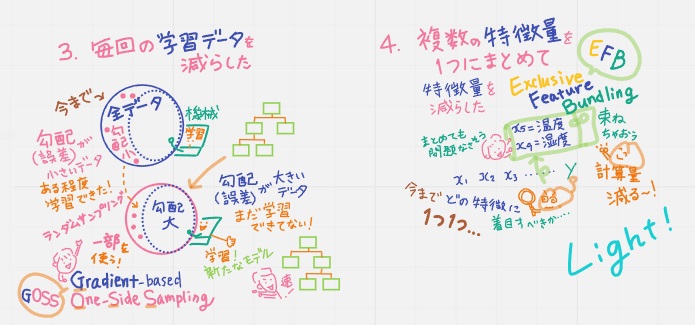
③GOSS(Gradient-based One-Side Sampling)
毎回の学習データを減らした(だからLight)
今までは全データを使って学習してたけど
・勾配(誤差)が大きいデータはまだ学習できていないからそのまま使う
・勾配(誤差)が小さいデータはある程度学習できたからランダムに抽出して一部を使う
結果、計算が速くなった。
④ExclusiveFeatureBundling
複数の特徴量を1つにまとめて特徴量を減らした(だからLight)
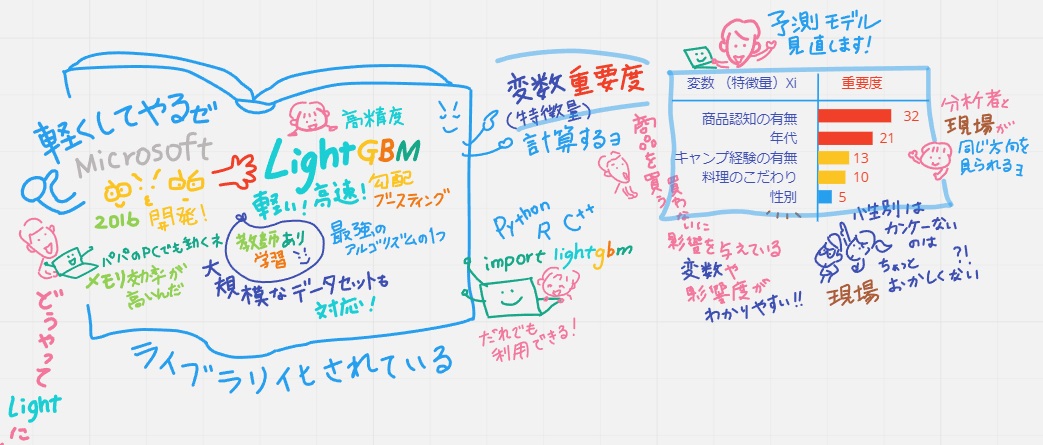
・「最強のアルゴリズム」と呼ばれるのは、Lightなだけが理由じゃない
ライブラリ化されていて誰でも利用できる点がすごい!
ライブラリで「変数(特徴量)重要度」が計算される。分かりやすく提示してくれる。分析者以外にも理解しやすい。現場の人とこれを見ながら、現場感とのズレも確認できたりと同じ方向を向いて話し合いができる。
だから多くの人たちに使われている。
パパ「もうLightGBMに任せちゃおう」
天才キッズ「気を付けて。ハイパーパラメータをチューニングするのはあくまでも人だよ」
・覚えておきたい3つのハイパーパラメータ
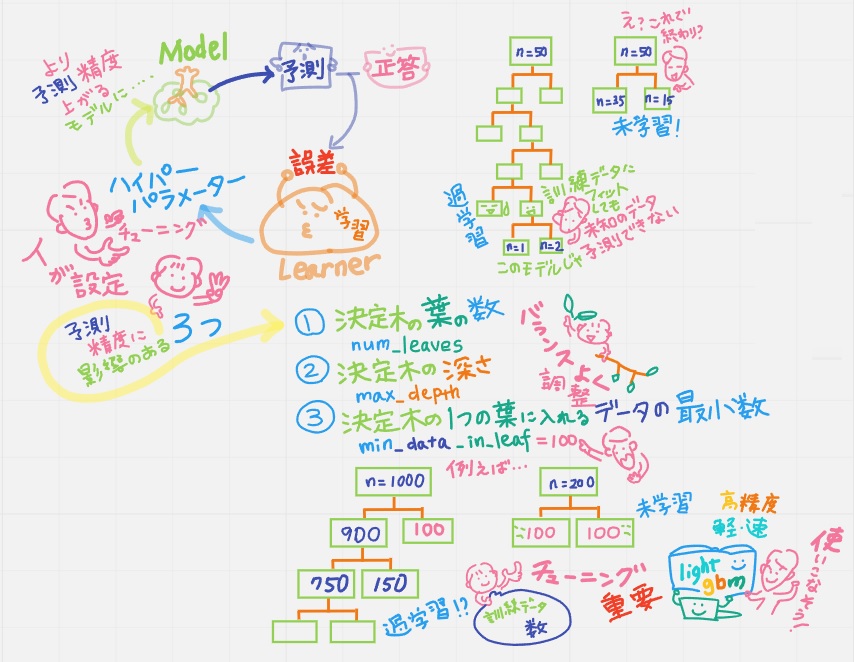
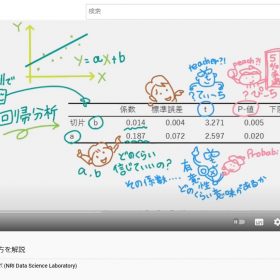
天才キッズ「モデルをつくって予測値を出して、正答との誤差から機械学習はさらにモデルを磨いていくんだけど、そこでハイパーパラメータをチューニングするのは人。LightGBMにもたくさんのパラメータがあるけれど、その中でも特に予測精度に影響のある3つは覚えておいてね」
①決定木の葉の数 num_leaves
葉の数が多すぎると過学習 少なすぎると未学習
②決定木の深さ max_depth
③決定木の1つの葉に入れるデータの最小数 min_data_in_leaf
例えば最小素100として
元データ数n=200⇒一回の分割で終わってしまったら…未学習
元データ数n=1000 (過学習になる?)とにかく
データ数を見ながらチューニングが重要だよ